Apache Hadoop インストール2015/07/28 |
|
Apache Hadoop をインストールします。
ここでは例として、以下の 3ノードを利用して分散処理できるよう設定します。
当例は 3ノードのみですが、Hadoop は大規模なデータを大規模なノード構成で処理する場合に、より真価を発揮します。
1) dlp.srv.world (マスターノード)
2) node01.srv.world (スレーブノード) 3) node02.srv.world (スレーブノード) |
|
| [1] | |
| [2] | 全ノードに Hadoop 用のユーザーを作成しておきます。 |
|
[root@dlp ~]# useradd -d /usr/hadoop hadoop [root@dlp ~]# chmod 755 /usr/hadoop [root@dlp ~]# passwd hadoop Changing password for user hadoop. New password: Retype new password: passwd: all authentication tokens updated successfully. |
| [3] | マスターノードに hadoop ユーザーでログインし、SSH 鍵ペア(ノーパスフレーズ)を作成して、各ノードに配布します。 |
|
[hadoop@dlp ~]$
ssh-keygen Generating public/private rsa key pair. Enter file in which to save the key (/usr/hadoop/.ssh/id_rsa): Created directory '/usr/hadoop/.ssh'. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /usr/hadoop/.ssh/id_rsa. Your public key has been saved in /usr/hadoop/.ssh/id_rsa.pub. The key fingerprint is: xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx hadoop@dlp.srv.world The key's randomart image is: # ローカルホスト含め各ノードに配布 [hadoop@dlp ~]$ ssh-copy-id localhost The authenticity of host 'localhost (::1)' can't be established. ECDSA key fingerprint is xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx. Are you sure you want to continue connecting (yes/no)? yes /bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed /bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys hadoop@localhost's password: Number of key(s) added: 1 Now try logging into the machine, with: "ssh 'localhost'" and check to make sure that only the key(s) you wanted were added.[hadoop@dlp ~]$ ssh-copy-id node01.srv.world [hadoop@dlp ~]$ ssh-copy-id node02.srv.world |
| [4] | 全ノードに Hadoop をインストールします。hadoop ユーザーで作業します。 以下のサイトで最新版を確認してダウンロードしてください。 ⇒ https://hadoop.apache.org/releases.html |
|
[hadoop@dlp ~]$ curl -O http://ftp.jaist.ac.jp/pub/apache/hadoop/common/hadoop-2.7.1/hadoop-2.7.1.tar.gz [hadoop@dlp ~]$ tar zxvf hadoop-2.7.1.tar.gz -C /usr/hadoop --strip-components 1
[hadoop@dlp ~]$
vi ~/.bash_profile # 最終行に追記
export HADOOP_HOME=/usr/hadoop
export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_YARN_HOME=$HADOOP_HOME export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native" export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin source ~/.bash_profile |
| [5] | マスターノードで Hadoop の設定をします。hadoop ユーザーで作業します。 |
|
# 全ノードでデータ用ディレクトリ作成 [hadoop@dlp ~]$ mkdir ~/datanode [hadoop@dlp ~]$ ssh node01.srv.world "mkdir ~/datanode" [hadoop@dlp ~]$ ssh node02.srv.world "mkdir ~/datanode"
[hadoop@dlp ~]$
vi ~/etc/hadoop/hdfs-site.xml # <configuration> ~ </configuration> 内に追記 <configuration>
<property>
</configuration>
<name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///usr/hadoop/datanode</value> </property> # スレーブノードに送信 [hadoop@dlp ~]$ scp ~/etc/hadoop/hdfs-site.xml node01.srv.world:~/etc/hadoop/ [hadoop@dlp ~]$ scp ~/etc/hadoop/hdfs-site.xml node02.srv.world:~/etc/hadoop/
[hadoop@dlp ~]$
vi ~/etc/hadoop/core-site.xml # <configuration> ~ </configuration> 内に追記 <configuration>
<property>
</configuration>
<name>fs.defaultFS</name> <value>hdfs://dlp.srv.world:9000/</value> </property> # スレーブノードに送信 [hadoop@dlp ~]$ scp ~/etc/hadoop/core-site.xml node01.srv.world:~/etc/hadoop/ [hadoop@dlp ~]$ scp ~/etc/hadoop/core-site.xml node02.srv.world:~/etc/hadoop/
[hadoop@dlp ~]$
[hadoop@dlp ~]$ sed -i -e 's/\${JAVA_HOME}/\/usr\/java\/default/' ~/etc/hadoop/hadoop-env.sh # スレーブノードに送信 [hadoop@dlp ~]$ scp ~/etc/hadoop/hadoop-env.sh node01.srv.world:~/etc/hadoop/ [hadoop@dlp ~]$ scp ~/etc/hadoop/hadoop-env.sh node02.srv.world:~/etc/hadoop/
mkdir ~/namenode
[hadoop@dlp ~]$
vi ~/etc/hadoop/hdfs-site.xml # <configuration> ~ </configuration> 内に追記 <configuration>
<property>
</configuration>
<name>dfs.namenode.name.dir</name> <value>file:///usr/hadoop/namenode</value> </property>
[hadoop@dlp ~]$
vi ~/etc/hadoop/mapred-site.xml # 新規作成 <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
[hadoop@dlp ~]$
vi ~/etc/hadoop/yarn-site.xml # <configuration> ~ </configuration> 内に追記 <configuration>
<property>
</configuration>
<name>yarn.resourcemanager.hostname</name> <value>dlp.srv.world</value> </property> <property> <name>yarn.nodemanager.hostname</name> <value>dlp.srv.world</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
[hadoop@dlp ~]$
vi ~/etc/hadoop/slaves # 全ノード名を追記 (localhost は削除)
dlp.srv.world
node01.srv.world node02.srv.world |
| [6] | ネームノードをフォーマットして Hadoop を起動します。 |
|
[hadoop@dlp ~]$ hdfs namenode -format 15/07/28 19:58:14 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = dlp.srv.world/10.0.0.30 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.7.1 ..... ..... 15/07/28 19:58:17 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at dlp.srv.world/10.0.0.30 ************************************************************/[hadoop@dlp ~]$ start-dfs.sh Starting namenodes on [dlp.srv.world] dlp.srv.world: starting namenode, logging to /usr/hadoop/logs/hadoop-hadoop-namenode-dlp.srv.world.out dlp.srv.world: starting datanode, logging to /usr/hadoop/logs/hadoop-hadoop-datanode-dlp.srv.world.out node02.srv.world: starting datanode, logging to /usr/hadoop/logs/hadoop-hadoop-datanode-node02.srv.world.out node01.srv.world: starting datanode, logging to /usr/hadoop/logs/hadoop-hadoop-datanode-node01.srv.world.out Starting secondary namenodes [0.0.0.0] 0.0.0.0: starting secondarynamenode, logging to /usr/hadoop/logs/hadoop-hadoop-secondarynamenode-dlp.srv.world.out[hadoop@dlp ~]$ start-yarn.sh starting yarn daemons starting resourcemanager, logging to /usr/hadoop/logs/yarn-hadoop-resourcemanager-dlp.srv.world.out dlp.srv.world: starting nodemanager, logging to /usr/hadoop/logs/yarn-hadoop-nodemanager-dlp.srv.world.out node02.srv.world: starting nodemanager, logging to /usr/hadoop/logs/yarn-hadoop-nodemanager-node02.srv.world.out node01.srv.world: starting nodemanager, logging to /usr/hadoop/logs/yarn-hadoop-nodemanager-node01.srv.world.out # 確認 (以下のように起動していれば OK) [hadoop@dlp ~]$ jps 2130 NameNode 2437 SecondaryNameNode 2598 ResourceManager 2710 NodeManager 3001 Jps 2267 DataNode |
| [7] | 付属のサンプルプログラムを実行し、動作確認します。 |
|
# ディレクトリ作成 [hadoop@dlp ~]$ hdfs dfs -mkdir /test
# ローカルにある NOTICE.txt を /test にコピー [hadoop@dlp ~]$ hdfs dfs -copyFromLocal ~/NOTICE.txt /test
# 内容を確認 [hadoop@dlp ~]$ hdfs dfs -cat /test/NOTICE.txt This product includes software developed by The Apache Software Foundation (http://www.apache.org/). # サンプルプログラム実行 [hadoop@dlp ~]$ hadoop jar ~/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount /test/NOTICE.txt /output01 15/07/28 19:28:47 INFO client.RMProxy: Connecting to ResourceManager at dlp.srv.world/10.0.0.30:8032 15/07/28 19:28:48 INFO input.FileInputFormat: Total input paths to process : 1 15/07/28 19:28:48 INFO mapreduce.JobSubmitter: number of splits:1 ..... ..... # 実行結果を確認 [hadoop@dlp ~]$ hdfs dfs -ls /output01 Found 2 items -rw-r--r-- 2 hadoop supergroup 0 2015-07-29 14:29 /output01/_SUCCESS -rw-r--r-- 2 hadoop supergroup 123 2015-07-29 14:29 /output01/part-r-00000 # 結果の内容を確認 (各ワードのカウント数が結果として出力されている) [hadoop@dlp ~]$ hdfs dfs -cat /output01/part-r-00000 (http://www.apache.org/). 1 Apache 1 Foundation 1 Software 1 The 1 This 1 by 1 developed 1 includes 1 product 1 software 1 |
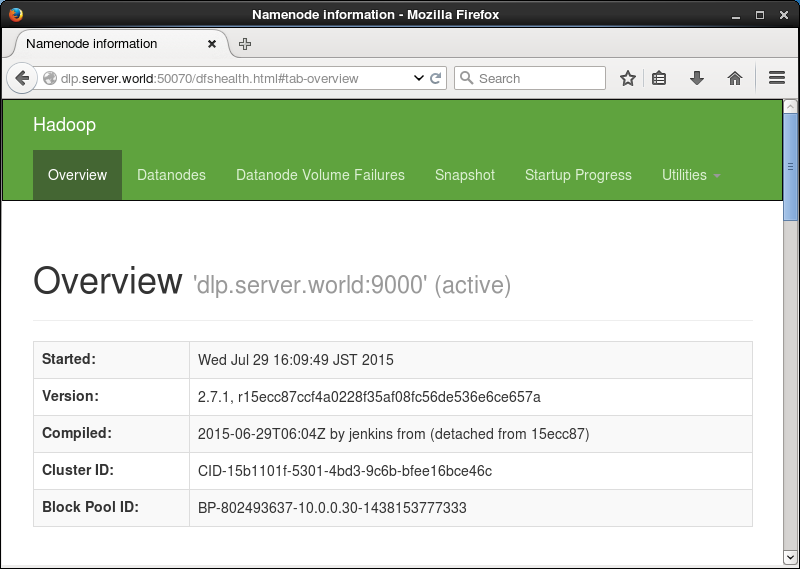
| [8] | 「http://(サーバーのホスト名またはIPアドレス):50070/」にアクセスすると、概要が確認できます。 |
|
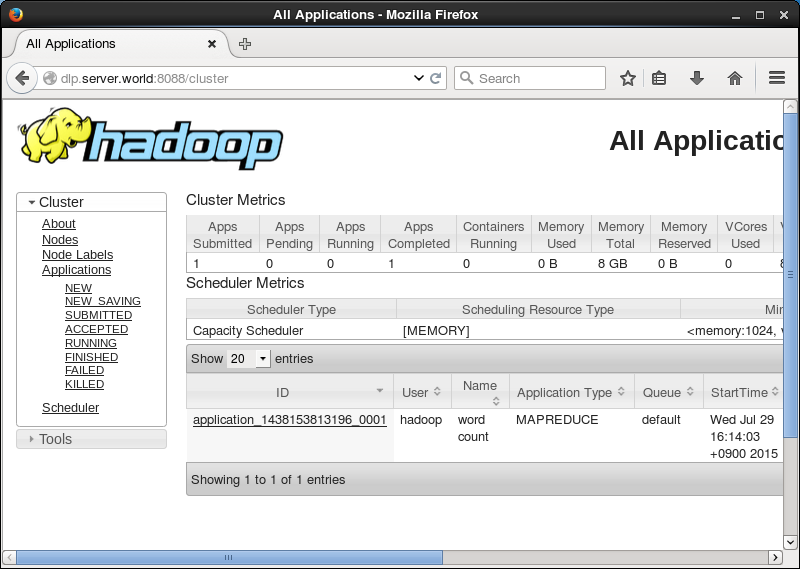
| [9] | 「http://(サーバーのホスト名またはIPアドレス):8088/」にアクセスすると、クラスターの情報が確認できます。 |
|
関連コンテンツ